
· Development · 14 min read
How we rebuilt our API using long-lived workflows
Nuon is an infrastructure company that enables companies to create a BYOC (bring your own cloud) version of their app. We connect to your existing tooling and product and allow you to create a fully managed version of your app that runs in your customer's cloud account.

After a year of using Temporal to power our provisioning layer, we went all in and rebuilt our API using long-lived workflows to model real-life infrastructure.
Nuon is an infrastructure company that enables companies to create a BYOC (bring your own cloud) version of their app. We connect to your existing tooling and product and allow you to create a fully managed version of your app that runs in your customer’s cloud account.
Building on Temporal
I’ve spent the past decade working on distributed systems that deal with infrastructure and data. If there’s one thing I’ve internalized, it’s that infrastructure engineering is as much about building features as it is about designing around failures.
When we set out to build Nuon, we knew that every provisioning step in our platform would be prone to end-customer interference, permissions issues, quota problems, and just the day-in and day-out of software system failure.
When you deploy an application into a new customer’s account, many things have to come together to make this work:
- account access + permission in the customer’s cloud account
- provisioning network or integrating with existing networks
- provisioning compute + orchestration infrastructure (like Kubernetes)
- provision application infrastructure
- deploy the application (containers, helm charts, and more)
Every step is prone to failure — from quota issues to insufficient permissions, customer interference, or conflicting objects. Even something as simple as billing not being set up in the end user’s account is an issue we must work around.
When building Nuon, one of our core beliefs was that working around these errors, mitigating, healing, and allowing for manual remediation where needed was a core part of making our product experience smooth.
Early Temporal Usage
Starting with Temporal was a no-brainer for us — Temporal has two core concepts that made it easy for us to model many of the different provisioning, de-provisioning, and deployment steps that enable us to run software in customer accounts.
Temporal has a concept of workflows and activities — workflows are how you design long chains of steps that need to come together, and activities are the individual steps in each. Activities represent real-life operations (API calls, jobs, and more) and are orchestrated, scheduled, and retried by workflows.
Nuon’s data model includes the following four objects:
- orgs — a “tenant” in our system which belongs to one of our customers
- apps — a deployable product that runs in the customer’s cloud account
- components — a part of an app, such as a helm chart, container, or terraform module
- installs — a fully running version of an app in a customer’s cloud account
Using Temporal, we modeled each part of our product using workflows. Each domain has several jobs executed as child workflows, responsible for provisioning, de-provisioning, syncing artifacts, deploying software, monitoring, and more.
A Tale of Two Stacks
Over the past year, we’ve consistently been surprised at how simple Temporal makes things — we now have over 30 workflows, 100+ activities, and many long chains of jobs required — five different Temporal workers power these workflows. We process 1000s of workflows daily, from seconds to an hour.
Today, we call our Temporal workflow worker layer our orchestration layer. To date, we have primarily had a single engineer owning this layer, which handles all our deployments, provisioning, and more.
While our orchestration layer proved much easier than we thought to build and stabilize in the summer, we realized that the rest of our product needed to be more capable. Our product felt like it was barely scratching the surface of what our platform could do under the hood.
As it turns out, our API was holding us back and making it hard for us to productize the robust provisioning layer we had built using Temporal — and it almost felt like we had two products, one that was imperative and manual, and a lower level infrastructure layer that was more capable.
Taking a step back
When we set out to build Nuon, we opted to build the most straightforward API we could — and our API was starting to show its cracks. At the time, we were struggling to meet the needs of our customers and ship — even the simplest features became challenging to ship, and we were unable to move fast. As we started to diagnose and understand the problems, we identified three key areas:
- Our API was designed to be as CRUD-like as possible, making modeling the state of infrastructure, deployments, and state out in the wild very hard — and often, our API was outdated.
- How we treated workflows as “side-effects” instead of core concepts in the product meant hiding a lot of important visibility from our customers/product.
- Our data model needed to match our product.
Broadly, we realized that while we had an excellent provisioning layer — we had no orchestration layer in our product. Taking a step back, we realized that continuing to invest in our provisioning layer without revisiting how our API worked from first principles would lead to diminishing returns and would continue to slow us down.
Since we already used Temporal for our provisioning layer, we started by asking, “Is Temporal our source of truth?” and began working backward.
We set out to build a new API that solved the core problems we were having and set out with a few design goals for our API:
- must more easily maintain an accurate state for our infrastructure objects by modeling them more realistically
- should enable us to build auto-remediation, orchestration, and more automation in the platform
- should be at least 2/3x quicker to ship new features
Introducing Temporal Long-Lived Workflows
Even though we had been using Temporal for almost a year when we set out to build our new API, we knew we were leaving some capabilities on the table. We were aware of how Temporal Signals and Queries could allow you to pass state around and ask the status of workflows — but we had not evaluated long-lived workflows seriously in our product.
Long-lived Temporal workflows enable you to create an actor-based system to model real-life scenarios. A handful of great talks, such as this one, explain how Uber initially used Cadence (now Temporal) to treat different drivers as actors. Long-lived workflows enable you to create a process that models real-world systems or interactions and then send + receive messages to those actors to coordinate workflows.
Temporal long-lived workflows rely on three concepts:
- Signals — messages that tell a workflow to do something (similar to a write operation)
- Queries — messages that ask a workflow for statuses, state, and data (similar to a read operation)
- Signal Channels + Selectors — primitives to route and receive signals (similar to a queue)
With Temporal long-lived workflows, you can create a queue for each object in your database and then pass messages to and from it, modeling real-life interactions.
Once you have long-lived workflows in place, you can register different signals and their “side-effects” in each workflow worker:
func (a *AwaitSignals) Listen(ctx workflow.Context) {
log := workflow.GetLogger(ctx)
for {
selector := workflow.NewSelector(ctx)
selector.AddReceive(workflow.GetSignalChannel(ctx, "Signal1"), func(c workflow.ReceiveChannel, more bool) {
c.Receive(ctx, nil)
a.Signal1Received = true
log.Info("Signal1 Received")
})
Long Lived Workflows as Event Loops
As we evaluated long-lived workflows, it became clear we could use this programming model to power a new API that treated each of our core product objects as event loops. This would allow us to run a long-lived actor for each part of our system and send messages to/from each while giving us the primitives to synchronize jobs and maintain state.
This new programming model would allow us to build a better data model and, overnight, would remove most of the work we had to do to coordinate changes on individual installs and apps manually. By treating each object as its own event loop, we could build simple logic to ensure that only a single operation per object happened at a time and could queue other jobs.
We started by creating an event loop for each of the core objects in our system:
- orgs — event loop that handled provisioning data plane
- apps — event loop that handled managing resources for the app
- installs — event loop for managing provisioning, de-provisioning, and deployments
- components — event loop for managing builds, updates, and configs
Whenever a new object gets created in our API, we create a corresponding long-lived workflow that handles signals for that object and manages its lifecycle.
func (w *Workflows) InstallEventLoop(ctx workflow.Context, req InstallEventLoopRequest) error {
l := workflow.GetLogger(ctx)
signalChan := workflow.GetSignalChannel(ctx, req.InstallID)
selector := workflow.NewSelector(ctx)
selector.AddReceive(signalChan, func(channel workflow.ReceiveChannel, _ bool) {
var signal Signal
channelOpen := channel.Receive(ctx, &signal)
if !channelOpen {
l.Info("channel was closed")
return
}
var err error
switch signal.Operation {
case OperationProvision:
err = w.provision(ctx, req.InstallID, req.SandboxMode)
if err != nil {
l.Error("unable to provision", zap.Error(err))
return
}
case OperationReprovision:
With this event loop primitive in place, we unlocked an entirely different programming model. We’ve moved from a CRUD first API where most of the state in our product had to be fetched at read time, creating a poor UX and complicating our API, to a system where long-lived workflows are modeling real world objects, and acting as the source of truth.
Benefits of our new API
In early August, we rebuilt our entire API in about two weeks by going all in on long-lived Temporal workflows. Since then, we have scaled our API from 28 total endpoints to over 120+ internal + public endpoints and have not only seen a significant boost in our development velocity but have been able to completely redesign our product from an imperative and manual system into a self-remediating, automated and declarative system.
Furthermore, we have gone from 3.5 dedicated engineers building our API to a single person owning the API (and being contributed to by the team).
Almost four months later, I’m happy to say that not only have we fixed the problems we set out to with our original API, but we’ve also been able to evolve our product. This new programming model has allowed us to add a sandbox mode to our API, build new operational tooling for ourselves and our users, and transition from an imperative manual interface to a more declarative product experience.
Let’s dig into each of these benefits and the evolution of our API.
Managing state + tracking real-world infrastructure
When building our new API, we set out to ensure that each piece of infrastructure we managed could easily be monitored and the health of any object could be easily understood. Previously, this had meant asking the “source” whenever we were querying a status — something that was prone to failure, slow, and required a lot of work.
Today, our event loops are responsible for directly managing state in our database. Our event loops are modeled alongside our API and share the same database. Since each object has a corresponding event loop, that event loop can easily monitor status changes and keep the database up to date.
type UpdateStatusRequest struct {
InstallID string `validate:"required"`
Status string `validate:"required"`
StatusDescription string `validate:"required"`
}
func (a *Activities) UpdateStatus(ctx context.Context, req UpdateStatusRequest) error {
install := app.Install{
ID: req.InstallID,
}
res := a.db.WithContext(ctx).Model(&install).Updates(app.Install{
Status: req.Status,
StatusDescription: req.StatusDescription,
})
if res.Error != nil {
return fmt.Errorf("unable to update install: %w", res.Error)
}
After the initial “write” to the database, the event loop takes over and is the primary write path to update its object. This allows the natural cadence of retries, background jobs, and long-lived workflows that make up these event loops to emit and update state as they go.
Furthermore, as these event loops monitor and manage the status of different objects in the wild, they can also notify other parts of the stack using signals when failures, remediations, or additional provisioning happens.
Dependency management
One of our biggest challenges with our previous API was dependency management. Since our product comprises several objects that depend on one another but also take time to provision or de-provision, it is essential to ensure that each parent/child object waits for its dependencies when created or destroyed.
With our event-loop driven API, we now use workflow steps to ensure that we do not inadvertently delete or create objects before their parent or child objects have been created/destroyed. Using workflows, we can do this with a simple, imperative programming model:
func (w *Workflows) pollDependencies(ctx workflow.Context, installID string) error {
for {
var install app.Install
if err := w.defaultExecGetActivity(ctx, w.acts.Get, activities.GetRequest{
InstallID: installID,
}, &install); err != nil {
w.updateStatus(ctx, installID, StatusError, "unable to get install from database")
return fmt.Errorf("unable to get install and poll: %w", err)
}
if install.App.Status == "active" {
return nil
}
if install.App.Status == "error" {
w.updateStatus(ctx, installID, StatusError, "app is in failure state, waiting for remediation")
}
workflow.Sleep(ctx, defaultPollTimeout)
}
}
While this was possible to work around manually in our old API, it became nearly impossible to manage when things failed. This led to many situations where we could “leak” infrastructure,” allowing it to be deleted from the database without being properly cleaned up or destroyed. With these primitives in place, we can now poll for statuses of child or parent objects or use queries to ask for statuses.****
Coordination + queueing
We quickly learned that one of the most complex challenges we would face building Nuon would be managing the lifecycle of each install independently. Users should be able to push to Nuon without manually addressing each customer update requirement.
To correctly model this type of update lifecycle across thousands or millions of installs, we need to be able to coordinate + queue on each install. While most customers want the latest version of your product, others only want updates during specific days and times, and some enterprise customers even require that all updates be manually opted into and reviewed.
Each of our long-lived event loop workflows declares its own signal channel and processes signals synchronously while queueing the rest.
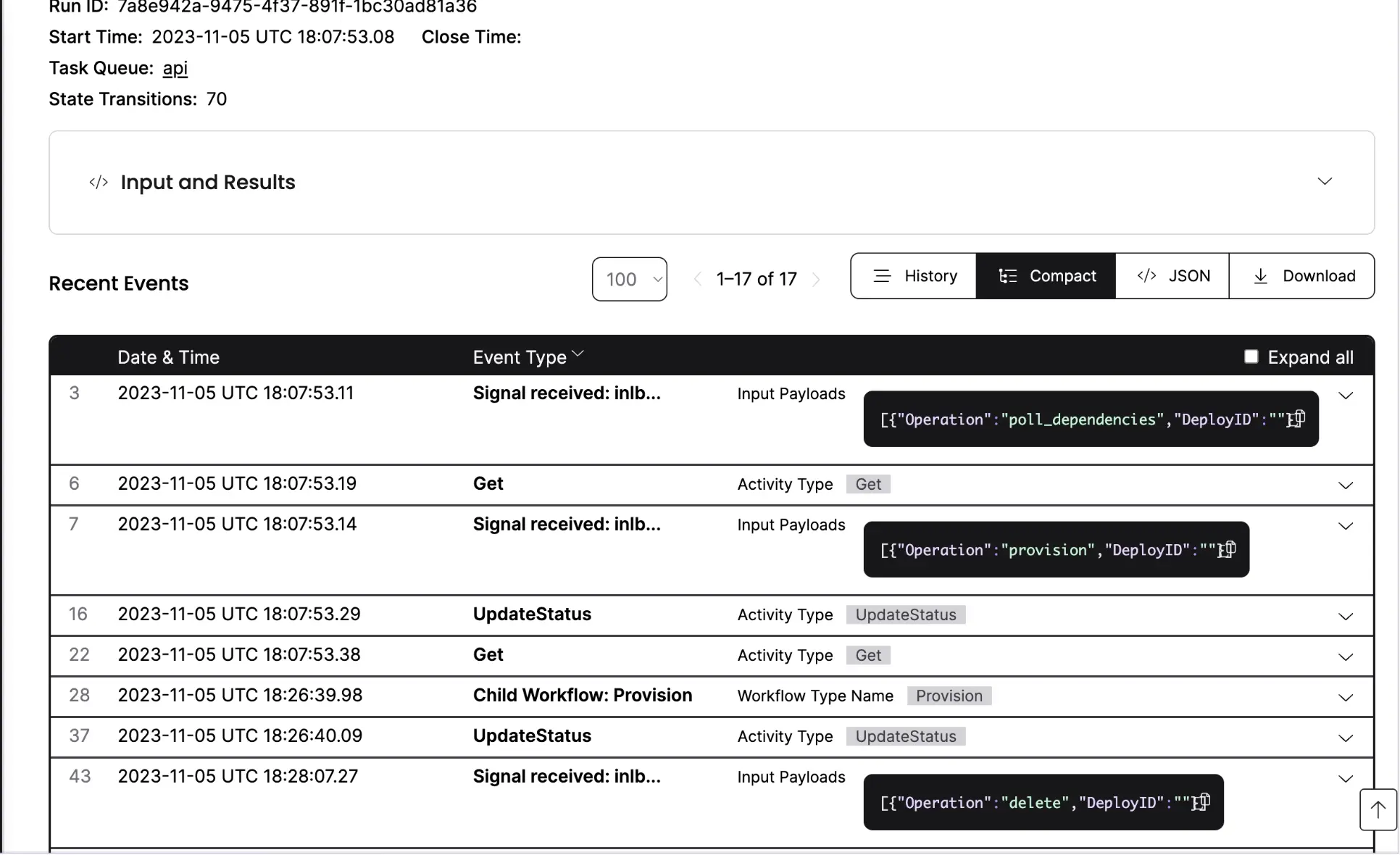
Channels and signals allow us to automatically queue jobs on each install and use different rules based on the install to decide when to apply those deploys.
Sandbox Mode
Using long-lived workflows, we created a “sandbox mode” for Nuon, enabling our users to use the entire product without actually modifying or building infrastructure. Sandbox mode allows a faster feedback loop and enables someone to setup their app with Nuon much faster, without having to worry about provisioning, destroying and managing real infrastructure.
Each long-lived workflow in our system is started with a sandboxMode flag, which is used to control whether the downstream provisioning layer is called:
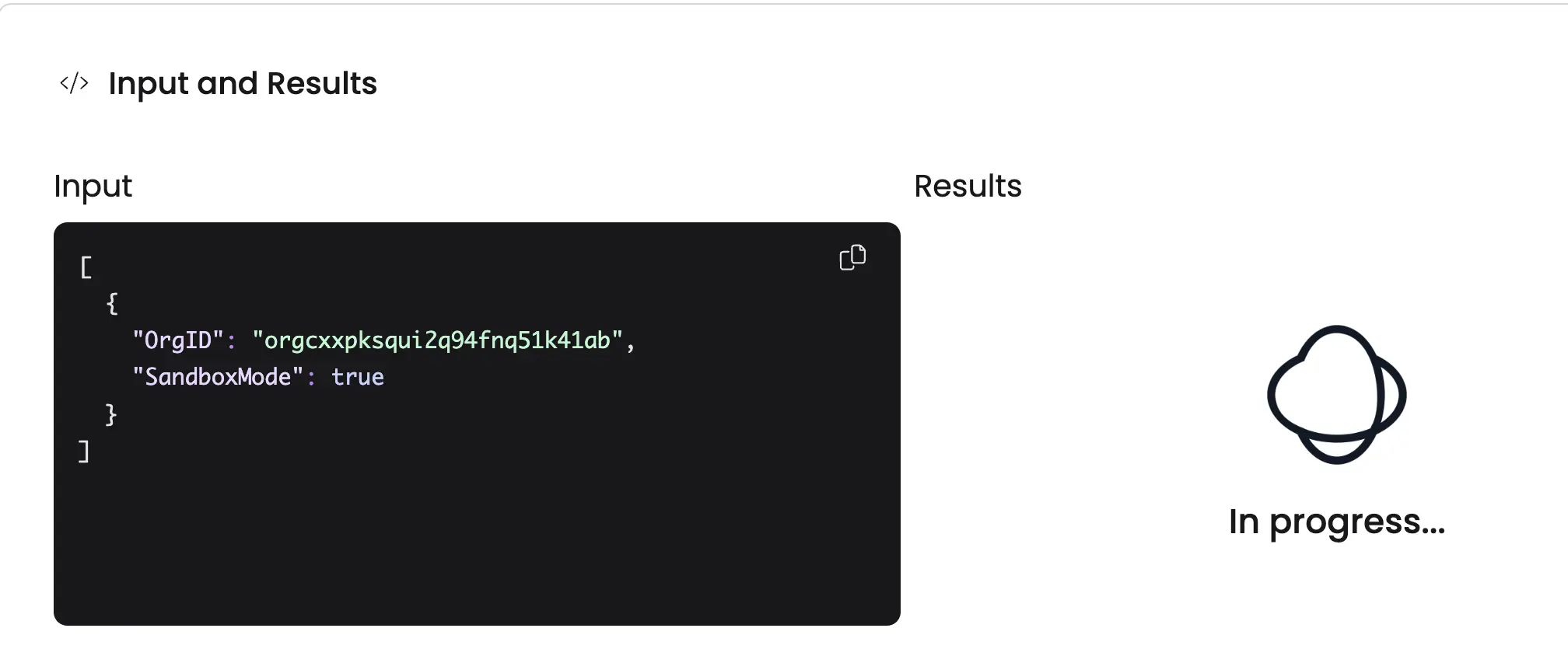
This allows us to easily mimic provisioning, by simply sleeping when sandbox-mode is invoked.
func (w *Workflows) execCreatePlanWorkflow(
ctx workflow.Context,
sandboxMode bool,
workflowID string,
req *planv1.CreatePlanRequest,
) (*planv1.CreatePlanResponse, error) {
l := workflow.GetLogger(ctx)
if sandboxMode {
l.Info("sandbox-mode enabled, sleeping for to mimic executing plan", zap.String("duration", w.cfg.SandboxSleep.String()))
workflow.Sleep(ctx, w.cfg.SandboxSleep)
return generics.GetFakeObj[*planv1.CreatePlanResponse](), nil
}
...
When sandbox mode is disabled, the downstream workflows are invoked as child workflows. With sandbox mode disabled, the workflow executes the actual provisioning step:
cwo := workflow.ChildWorkflowOptions{
TaskQueue: workflows.ExecutorsTaskQueue,
WorkflowID: workflowID,
WorkflowExecutionTimeout: time.Minute * 60,
WorkflowTaskTimeout: time.Minute * 30,
WorkflowIDReusePolicy: enumsv1.WORKFLOW_ID_REUSE_POLICY_TERMINATE_IF_RUNNING,
WaitForCancellation: true,
}
ctx = workflow.WithChildOptions(ctx, cwo)
var resp planv1.CreatePlanResponse
fut := workflow.ExecuteChildWorkflow(ctx, "CreatePlan", req)
Operational tooling
Since each object in our system is modeled via a long-lived workflow, we add new operations to create “side effects” to update, create, and destroy infrastructure using signals. Part of our API design depends on developing these signals and implementing handlers that act upon them.
case OperationPollDependencies:
err = w.pollDependencies(ctx, req.InstallID)
if err != nil {
l.Error("unable to poll dependencies", zap.Error(err))
return
}
case OperationProvision:
err = w.provision(ctx, req.InstallID, req.SandboxMode)
if err != nil {
l.Error("unable to provision", zap.Error(err))
return
}
case OperationReprovision:
err = w.reprovision(ctx, req.InstallID, req.SandboxMode)
if err != nil {
l.Error("unable to reprovision", zap.Error(err))
return
}
case OperationDelete:
Previously, we had to model these operations using scripts or CLIs. Now, we can expose them directly in our internal API and occasionally in our public API for customers.****
Concluding thoughts
When we set out to build Nuon, we knew that solving many distributed challenges that Temporal helps with would be vital to building a robust product. We just realized how powerful of a programming paradigm building our API on top of long-lived workflows would turn out to be.
Long-lived workflows have given us an actor-based model that has enabled us to build a robust, declarative, and self-healing product experience.
Stay tuned for more posts like this about how we are building Nuon! 🚀



